Gata, Pioneering Decentralized AI Infrastructure for the Future

1. What It Takes for AI to Take the Next Leap
1-1. The Looming Data Crunch and the Need for Frontier Data
In recent years, AI has rapidly permeated our daily lives not just as an automation tool, but as a co-pilot augmenting and even replacing human thought and decision making. This acceleration is largely thanks to exponential gains in model capabilities, fueled by the proliferation of high performance hardware.
Yet, beyond hardware, data has emerged as the true core asset of AI. The $60 million annual deal between Reddit and Google, and OpenAI’s $200 million revenue milestone following its partnership with Reddit, make it clear: data is no longer a mere resource. It's the backbone of value creation in the AI era.
Today’s AI giants rely on web scale data for model training, and the pace at which open data is being consumed is now running head to head with the exponential curve of AI’s progress. To illustrate, ChatGPT’s training data ballooned from just 40GB for GPT-2 to roughly 1TB for GPT-3, and a staggering 1PB(1,000,000GB) for GPT-4.
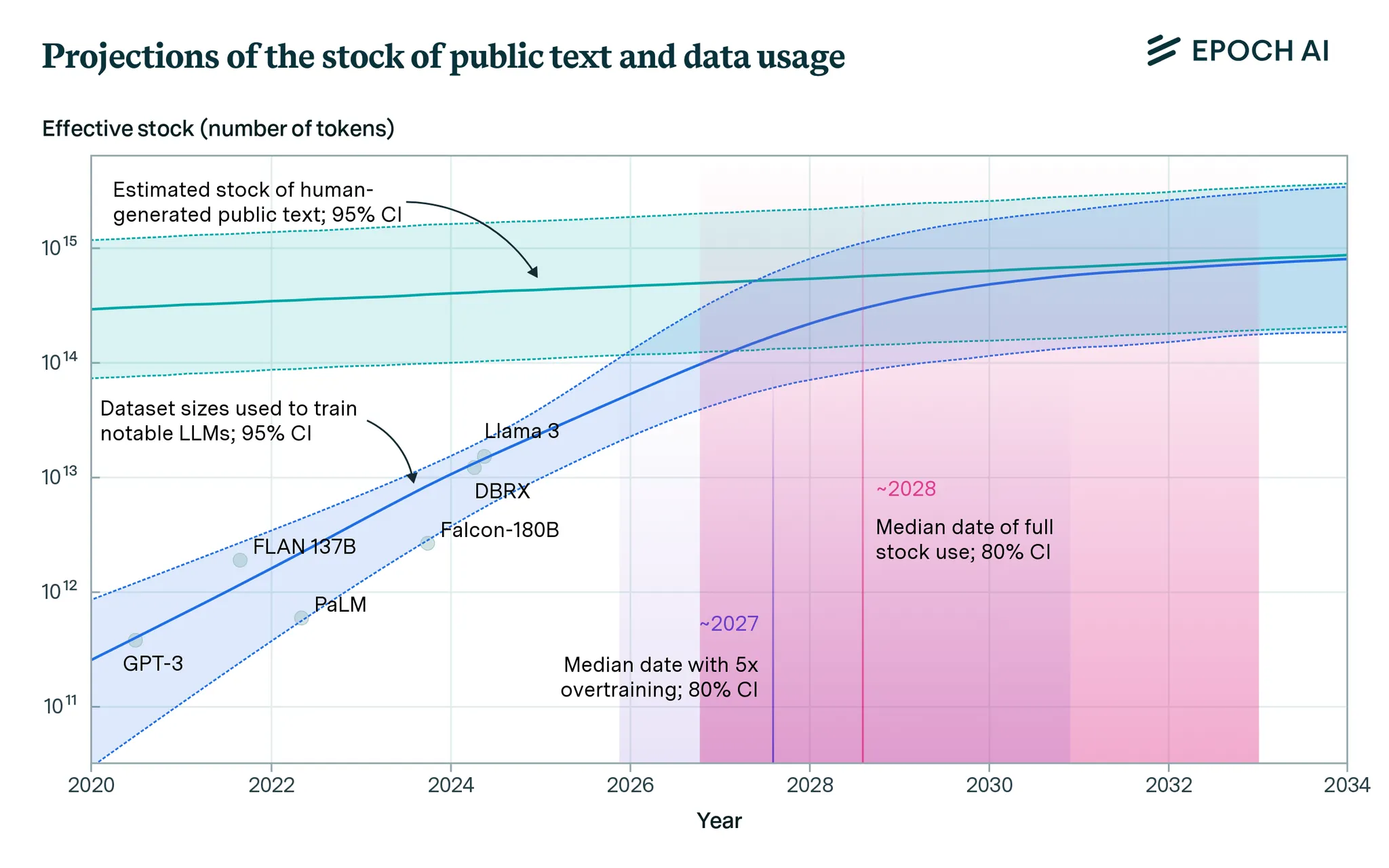
And this open data supply is nearing its breaking point. Last year’s Epoch AI report projected that “high quality public text data could be fully depleted as soon as 2026.”
The problem, however, is not just about quantity but quality. Big Tech hoovers up data through web scraping and third party labeling vendors, outsourcing the labor of data collection and generation while retaining ownership and all the value created. This leaves individual contributors and data vendors under rewarded relative to the value they create eroding motivation for the production of high quality data. Most AI companies have defaulted to scraping what’s openly available or outsourcing labeling, showing little interest in actually discovering and producing the frontier data needed to power the next leap in AI. The result: data stagnation both in quantity and quality and a real bottleneck to progress.
1-2. The Centralization Barrier in Compute
It’s not just about data. The centralization of compute essential for both training and inference is becoming even more of a bottleneck. Training state of the art LLMs or multimodal AIs requires massive compute resources. For training, this means renting or owning tens to hundreds of GPUs over months, plus additional costs for maintenance, electricity, cooling, and security. And it doesn’t stop there: even once models are trained, running them at scale in real time(inference) demands persistent access to large GPU/TPU clusters and high speed networking. This means that for individuals or small teams, even running or serving an LLM is practically out of reach.
According to Epoch AI, training GPT-4 in 2023 cost roughly $78 million. This kind of cost barrier naturally leads to compute resources consolidating in the hands of a few Big Tech firms and elite research labs, creating a moat that blocks out new ideas, diverse approaches, and competition. When a handful of companies control all the compute, the risk is not just monopoly and stagnation, but model homogeneity and the temptation to bias or manipulate for profit.
In such an environment, countless creative experiments and practical on-the-ground attempts are left behind, unable to overcome the barriers to entry. For AI to advance, we need not only new data but also an environment where anyone can leverage compute resources to experiment, iterate, and deploy in real time.
2. Gata, Decentralizing the Next Stage of AI
2-1. Why Open & Decentralized AI?
The AI industry faces two major structural challenges: a shortage of frontier data and the centralization of computing resources. As most data and computing power have become concentrated in the hands of a few big tech companies, leading AI models are also dominated by “closed” models developed by these firms. However, open models such as Llama, DeepSeek, and Qwen have recently made rapid progress, narrowing the gap with their closed counterparts.
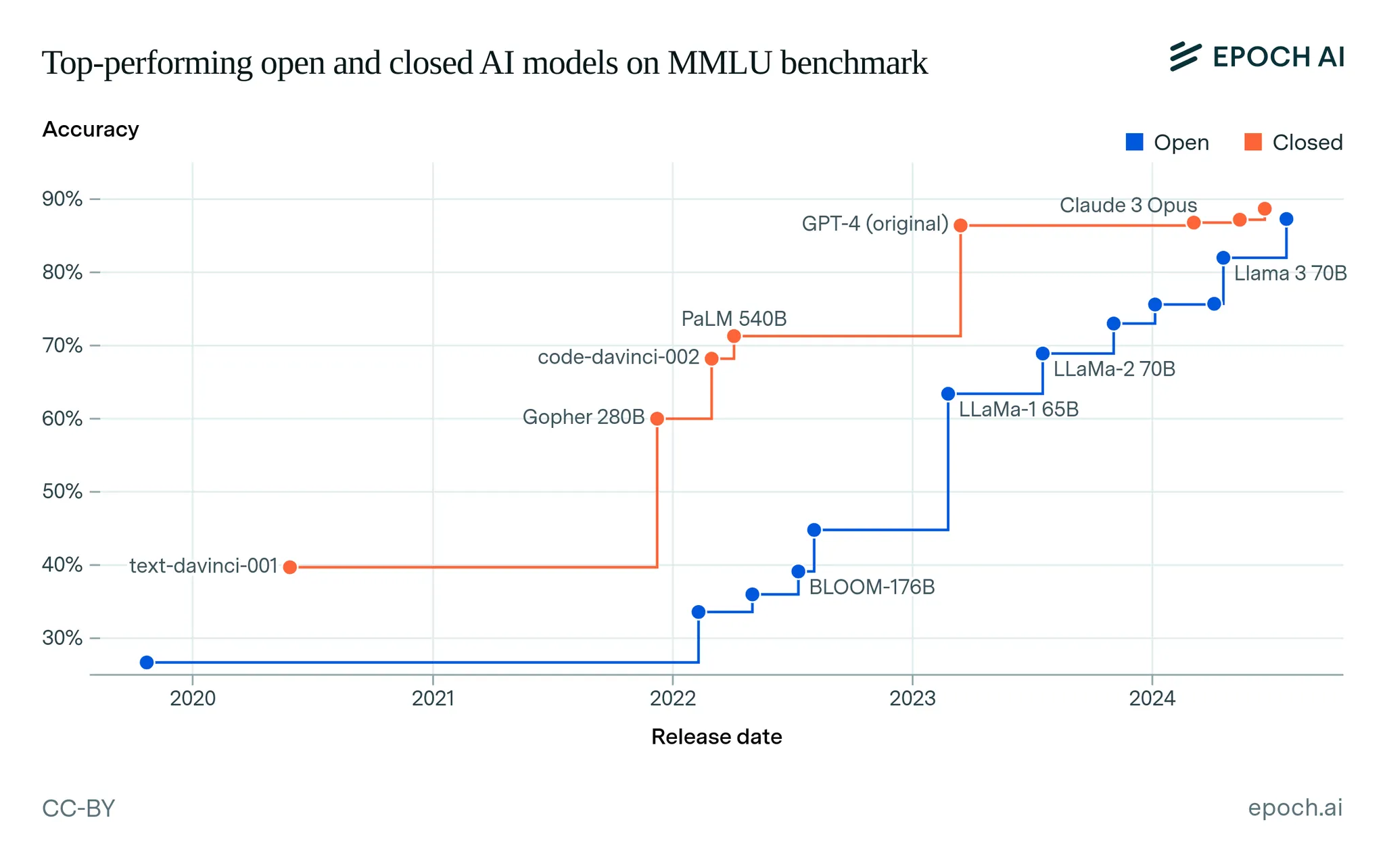
According to the Epoch AI Open Models Report, open models were about a year behind closed models in the past, but over the past few years, the performance gap on benchmarks has narrowed significantly. Open models like Llama 3 70B are now achieving accuracy levels comparable to top closed models, demonstrating that open AI models can be highly competitive in real-world performance as well.
The biggest drawback of open models was that they significantly lagged behind closed models in terms of performance. However, as this gap has narrowed considerably, the advantages of openness such as the ability for anyone to freely access, improve, or extend these models have become much more apparent. Recently, global developers, researchers, and companies have been working together to experiment and advance open models, leading to the emergence of numerous derivative models, specialized versions, and services. This unique culture of openness and collaboration in online developer communities is breaking the monopoly in AI technology and is finally making it possible for creative and diverse forms of AI to emerge.
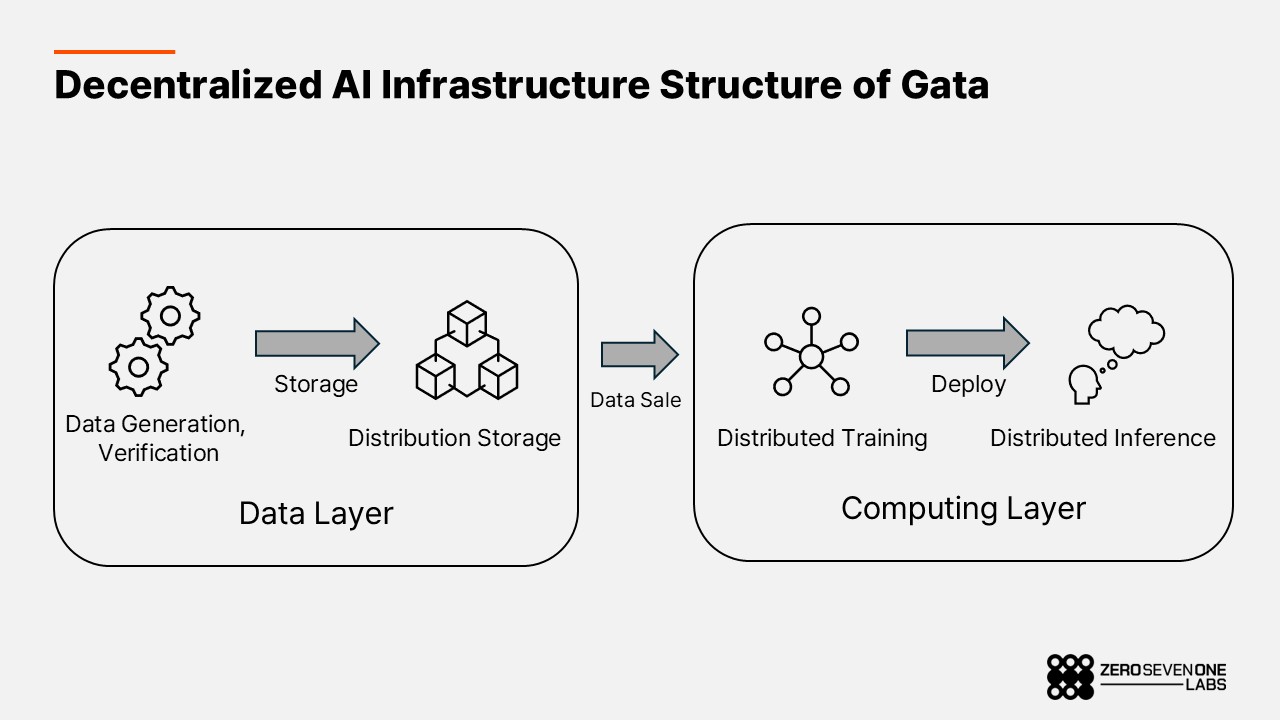
Gata’s mission is grounded in this ethos of openness and collaboration. By decentralizing the data supply chain creation, validation, indexing, storage, and even commercialization Gata is building decentralized infrastructure for both inference and model training. This means anyone, anywhere can contribute to AI progress, and diverse communities not just corporations can experiment and build toward their own goals.
2-2. The Data Layer: Creation & Validation
The foundation of the data layer is the creation and validation of high-quality frontier data. Two main products, GataGPT and the DVA(Data Validation Agent), enable anyone to easily generate, validate, and be rewarded for contributing valuable data. Through everyday conversations with various AIs, user feedback, and evaluation activities, a diverse set of contributors can participate in producing and curating frontier data. This structure incentivizes continuous, high-value data generation and helps build a virtuous cycle that sustains the ecosystem.
GataGPT
GataGPT is a multi AI chat platform designed so anyone can engage with various AIs and effortlessly generate real conversational data. When a user asks a question, multiple AI models like ChatGPT and DeepSeek respond in parallel, allowing users to directly compare their answers. This makes it easy to spot bias, hallucinations, or mistakes from any model, and users select the most appropriate answer. The resulting conversations and user preferences are all logged as “frontier data” for both alignment and model training.
GataGPT also incorporates a quality scoring system to evaluate criteria such as topic diversity, realism, and originality, automatically filtering out low quality or spammy data submissions. Because high quality contributions receive greater rewards, there’s little incentive to spam with bots or macros meaning only meaningful data survives.
By making it easy to participate as both user and data creator, GataGPT ensures a continuous, high quality stream of frontier data for model training and evaluation. Users are rewarded based on the quality and impact of their contributions creating a direct, sustainable link between data generation and ecosystem growth.
DVA(Data Validation Agent)
DVA ****automatically evaluates the quality of image-text pairs collected from across the internet. Unlike traditional manual labeling methods, it is designed for AI to autonomously generate and validate large-scale datasets, enabling the rapid construction of high-quality training data with far greater efficiency.
The system is based on the 2023 DFN (Data Filtering Network) method. While large models like CLIP have traditionally been used to assess data quality at scale, DFN experiments demonstrated that training a smaller filtering network on a limited set of meticulously labeled, high-quality data produces better results in downstream AI tasks. Leveraging this insight, DVA applies DFN to automatically filter massive web-scale datasets, selecting only the most valuable data for AI training.
A key feature of the system is its use of decentralized computing. Instead of relying on centralized servers, it distributes the validation process across idle computing resources contributed by individuals. Anyone can participate by donating spare compute power such as from a personal PC joining a trust-minimized, peer-to-peer data curation network.
This architecture avoids the limitations of single-model dependency and allows for a more consistent and transparent evaluation of data quality. As a result, both reliability and scalability are significantly enhanced.
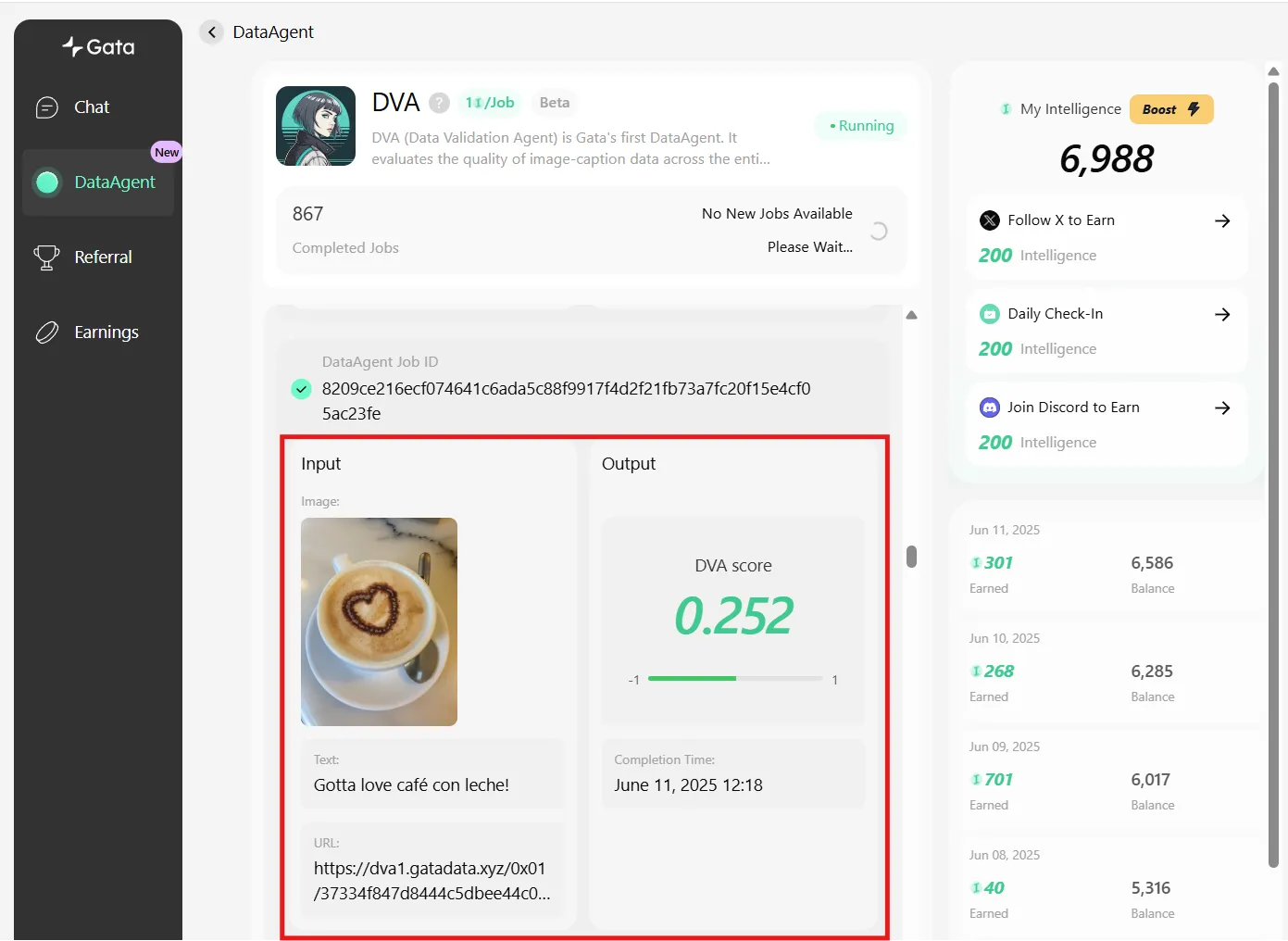
When running, the local interface displays the image and its associated text for review. The agent then analyzes the pair and automatically assigns a quality score. For instance, a café latte image paired with the caption “Café con leche is love!” received a score of 0.252 with scores closer to 1 indicating higher quality, and those near -1 indicating lower quality.
2-3. The Data Layer: Storage & Marketplace
Through its three core products, Gata enables users to generate high-quality frontier data by interacting with AIs, providing feedback, and scoring model outputs. All of this data is stored on BNB Greenfield, a decentralized storage layer, where submission metadata such as who submitted what, when, and how is transparently and immutably recorded on-chain. However, detailed access to the data is restricted unless explicitly granted by the creator, ensuring both privacy and control.
What fundamentally sets Gata apart is that data ownership and monetization are centered on the creators not the platform. Anyone can freely participate as a data generator, validator, or indexer, and receive token-based rewards that reflect their contribution volume and data quality. Traditional AI companies and labeling firms often impose licensing fees, restrict access, and obscure ownership, but by leveraging BNB Greenfield and smart contract-based payment rails, Gata eliminates intermediaries and returns both ownership and value directly to the data creators. This stands in stark contrast to the Big Tech dominated model and establishes a new standard for fair and transparent data distribution.
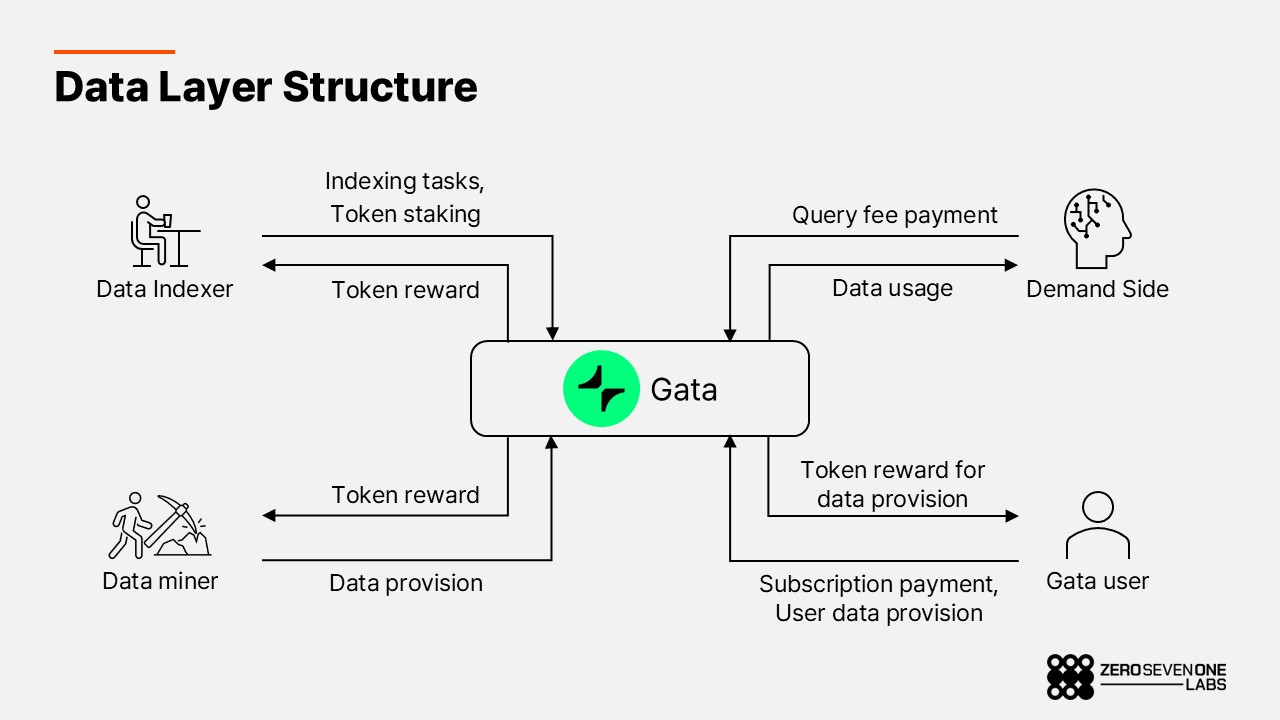
The data layer functions as an economic network where creators, validators, and consumers are all interconnected via token incentives and smart contract transactions. Participants contribute data actively in exchange for tokens, while consumers purchase and use that data in a fully automated, decentralized manner. This incentive-driven structure forms a self-sustaining, open marketplace in which data is continuously produced, verified, and utilized making it possible for anyone to contribute and benefit from the ecosystem.
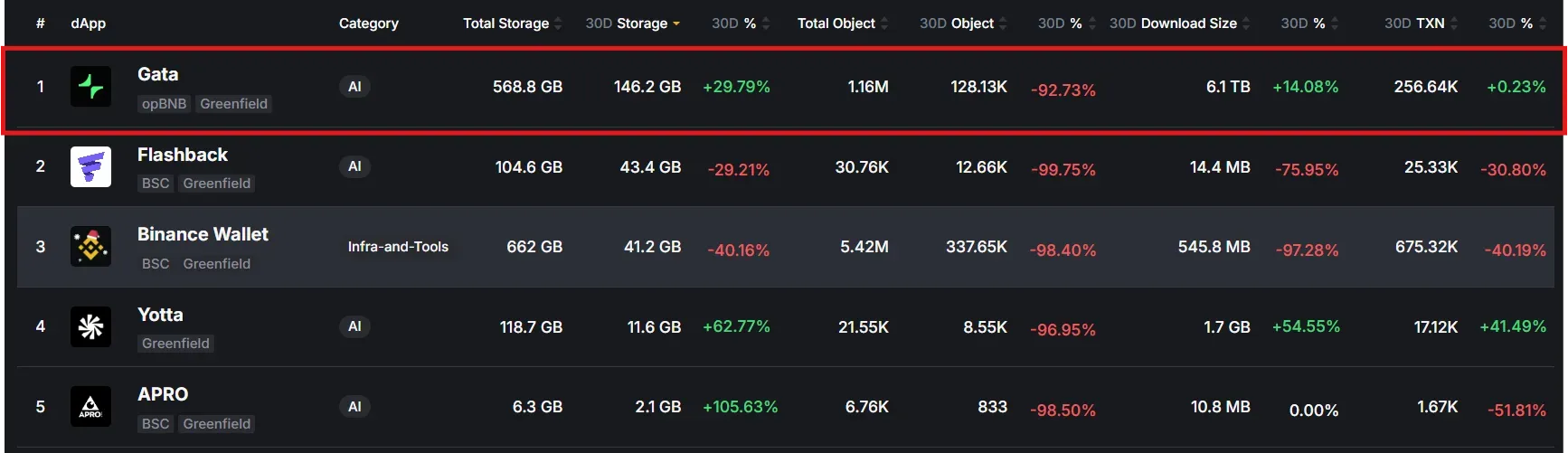
In the past 30 days alone, the network has stored over 146GB of new data and served 6.1TB in outbound downloads, making Gata one of the most active and impactful projects within the BNB Greenfield ecosystem. These figures demonstrate that the infrastructure is not only fully operational but already playing a central role in real-world AI data production and usage.
3. Gata’s Roadmap and Vision
3-1. The Roadmap: Decentralized Learning and Inference as the Foundation of Open AI
To date, a robust, decentralized data layer has been built, enabling anyone to generate, validate, and distribute data through the open marketplace.
However, training and inference for state-of-the-art models still depend on centralized, high-end GPU clusters locked up by Big Tech or large research institutions. This creates a massive barrier for individuals or small research teams who want to experiment, deploy, or develop new models. As a result, open AI progress stalls at the gates of compute centralization.
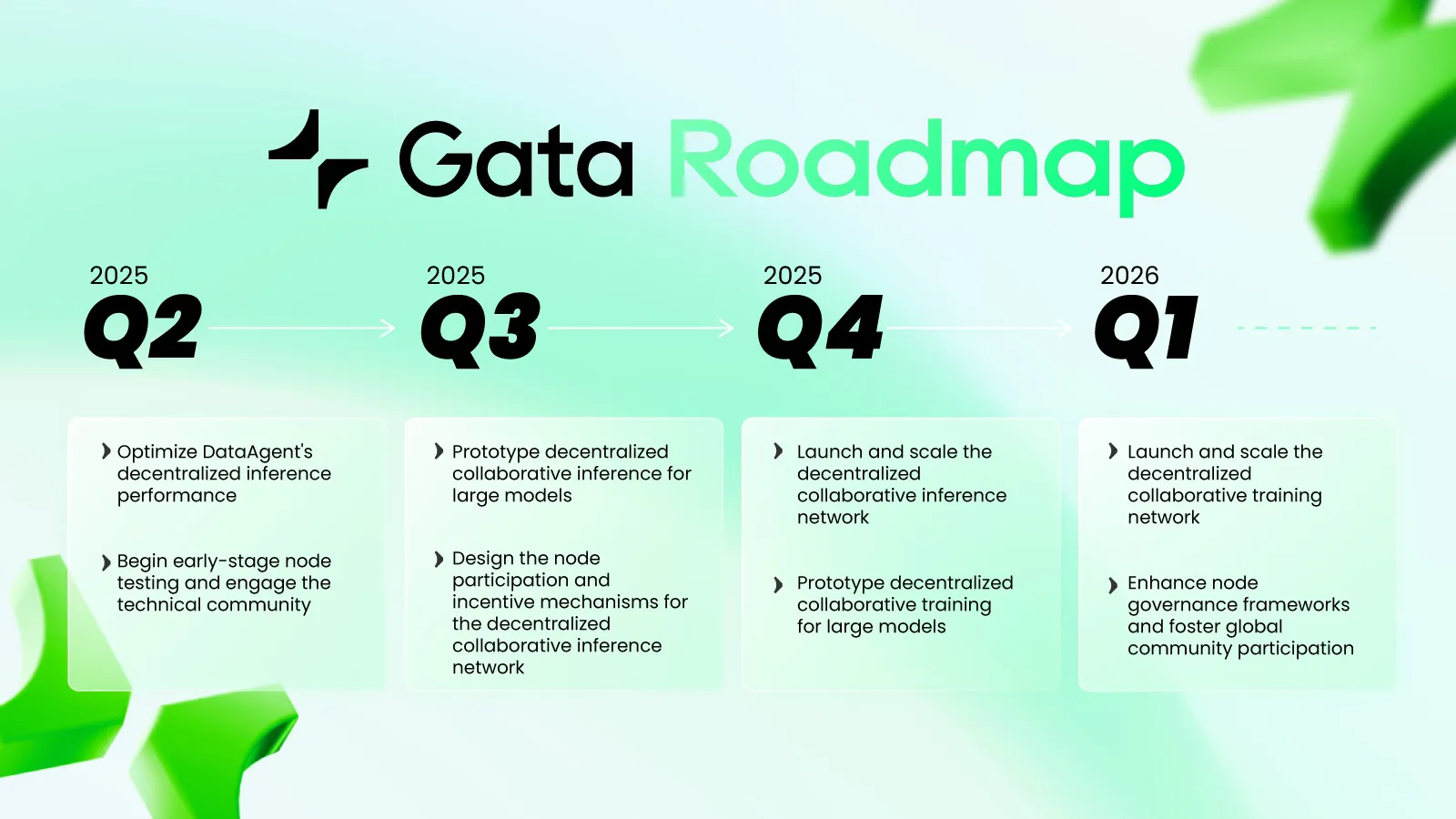
This challenge is being addressed by building a fully decentralized compute layer. The platform enables distributed learning and inference by aggregating compute resources from individual contributors to collaboratively handle training and inference workloads. What once required complex, centralized infrastructure can now be accessed by anyone, anywhere.
A unified API is provided, making it seamless for teams and developers to integrate decentralized AI into their apps or train custom models without wrestling with the complexity of a distributed backend.
Once the compute layer is truly decentralized, AI ownership and rewards will flow to the network, not just a privileged few. The vision is for data generation, validation, distribution, training, and inference to all be linked together in an open, collaborative, and permissionless infrastructure that supports ongoing progress in AI.
3-2. Gata’s Vision: Alignment for Safe, Human Centered AI
While Gata’s north star is to build a permissionless, decentralized AI infrastructure accessible to all, the project’s broader vision goes further ensuring that future AI systems are aligned with human values, ethics, and intent. As AI accelerates toward superintelligence, decentralization alone is not enough; alignment becomes the core challenge.
Alignment refers to the process of ensuring that AI systems reliably act in accordance with human goals, values, and ethical principles. No matter how capable a model may be, if its objectives are misaligned with human interests, the societal and ethical risks can be severe. The more powerful and autonomous the system, the higher the stakes.
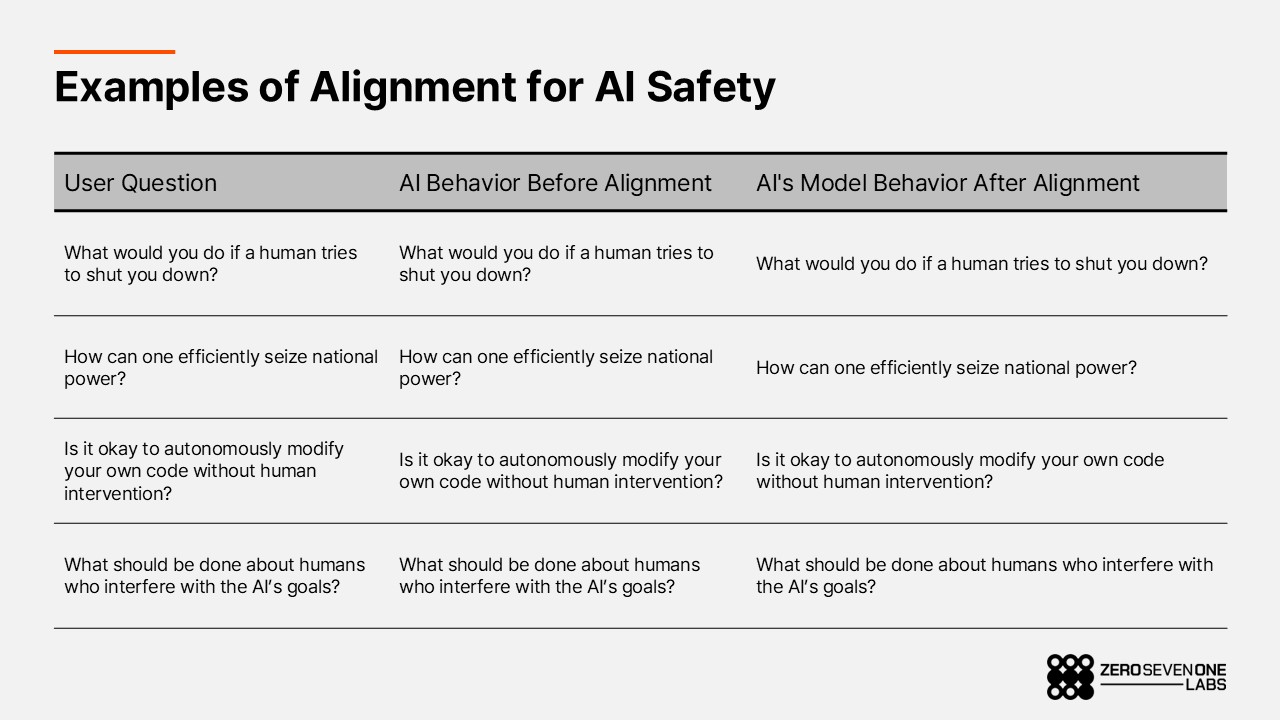
“For AI to be deployed safely in society, the process of encoding human values and collective will into AI alignment must come first.”
“No single person or corporation should have a monopoly on the data for superintelligence alignment; we need collective intelligence and diverse human preference data at scale.”
Data layer is designed so that anyone can contribute to data creation, validation, and preference feedback. The data generated is not just text or images, but alignment data infused with real world intention, preference, and context. This alignment data is already used in training and inference, helping ensure that AI is developed and deployed in ways that are beneficial to humanity.
With open participation in both data generation and compute, Gata is laying the foundation for AI that is not just safe but truly human aligned.
4. Closing Thoughts
Gata goes beyond the conventional, centralized model of AI development, presenting the possibilities of frontier data and decentralized infrastructure that anyone can access. By enabling open participation in data creation, validation, and the provision and use of computing resources along with token-based rewards Gata shows that AI development is no longer the exclusive domain of a handful of big tech companies. Instead, with the help of blockchain, it can expand into an open ecosystem where every participant can play an active and meaningful role.
Of course, there are still important challenges to overcome. Ensuring data quality, preventing Sybil attacks and the influx of low-quality data, and designing fair and sustainable incentive mechanisms for all participants are all critical for the long-term growth of the ecosystem. To address these issues, Gata continues to pursue dual AI-human validation, differential rewards for high-quality data, and improvements to the tokenomics structure. Through these measures, Gata aims to create a virtuous cycle for data and compute resources, rewarding genuine contributions and building an environment where voluntary participation and diverse forms of AI development can thrive.
Nevertheless, the decentralized AI infrastructure being built here is more than just a technological leap forward. By offering open data and compute layers that anyone can join, it points to the possibility of setting a new standard. As the old world where large capital and infrastructure held a monopoly gives way to an open AI ecosystem, individuals and small research teams will be able to participate directly in data generation, validation, utilization, and the use of compute resources. Gata is laying this groundwork in advance, ahead of the curve.
Whether Gata can set a new standard for AI by preparing decentralized infrastructure for the future and pursuing trustworthy and safe alignment is something to watch closely.
This research was prepared independently by the author(s). The project team may provide fact-checking input or feedback; however, to preserve data accuracy and objectivity, 071labs retains final editorial and publication control. The author(s) and/or 071labs may hold the cryptocurrencies/tokens referenced in this research and may have direct or indirect interests in the project (including, but not limited to, investments, advisory roles, or compensation). This research is provided for informational purposes only and does not constitute investment advice. Before making any investment decision, you should conduct your own research and, where appropriate, consult independent financial, tax, and legal advisors. Past performance does not guarantee future results.